#include <cmath>#include <cstdio>#include <cfloat>#include <climits>#include <algorithm>#include <functional>#include <sstream>#include <string>#include <inttypes.h>#include <mkl_blas.h>#include <mkl_cblas.h>#include <mkl_vsl.h>#include <mkl_vsl_functions.h>#include <mkl_version.h>#include <cuda.h>#include <cublas_v2.h>#include <curand.h>#include <cusolverDn.h>#include "./half.h"#include "./half2.h"#include "./bfloat.h"#include "./logging.h"
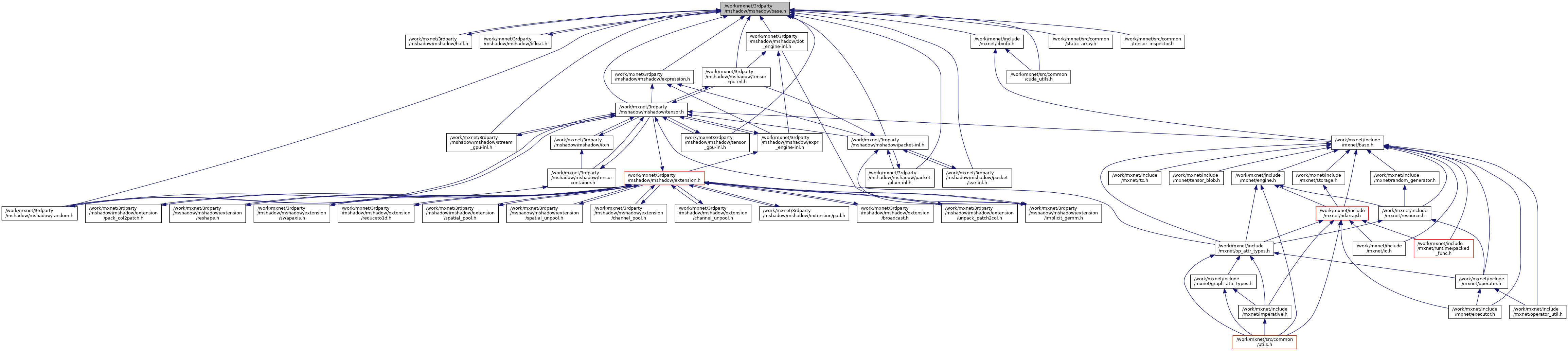
Go to the source code of this file.
Namespaces | |
| mshadow | |
| overloaded + operator between half_t and bf16_t | |
| mshadow::op | |
| namespace for operators | |
| mshadow::sv | |
| namespace for savers | |
| mshadow::isnan_typed | |
| determines if the given floating point number is not a number | |
| mshadow::isinf_typed | |
| determines if the given floating point number is a positive or negative infinity | |
| mshadow::red | |
| namespace for potential reducer operations | |
| mshadow::red::limits | |
Macros | |
| #define | MSHADOW_STAND_ALONE 0 |
| if this macro is define to be 1, mshadow should compile without any of other libs More... | |
| #define | MSHADOW_ALLOC_PAD true |
| whether do padding during allocation More... | |
| #define | MSHADOW_MIN_PAD_RATIO 2 |
| x dimension of data must be bigger pad_size * ratio to be alloced padded memory, otherwise use tide allocation for example, if pad_ratio=2, GPU memory alignement size is 32, then we will only allocate padded memory if x dimension > 64 set it to 0 then we will always allocate padded memory More... | |
| #define | MSHADOW_FORCE_STREAM 1 |
| force user to use GPU stream during computation error will be shot when default stream NULL is used More... | |
| #define | MSHADOW_USE_CBLAS 0 |
| use CBLAS for CBLAS More... | |
| #define | MSHADOW_USE_MKL 1 |
| use MKL for BLAS More... | |
| #define | MSHADOW_USE_CUDA 1 |
| use CUDA support, must ensure that the cuda include path is correct, or directly compile using nvcc More... | |
| #define | MSHADOW_USE_CUDNN 0 |
| use CUDNN support, must ensure that the cudnn include path is correct More... | |
| #define | MSHADOW_USE_CUSOLVER MSHADOW_USE_CUDA |
| use CUSOLVER support More... | |
| #define | MSHADOW_OLD_CUDA 0 |
| seems CUDAARCH is deprecated in future NVCC set this to 1 if you want to use CUDA version smaller than 2.0 More... | |
| #define | MSHADOW_IN_CXX11 0 |
| macro to decide existence of c++11 compiler More... | |
| #define | MSHADOW_USE_SSE 1 |
| whether use SSE More... | |
| #define | MSHADOW_USE_F16C 1 |
| whether use F16C instruction set architecture extension More... | |
| #define | MSHADOW_USE_NVML 0 |
| whether use NVML to get dynamic info More... | |
| #define | MSHADOW_FORCE_INLINE inline __attribute__((always_inline)) |
| #define | MSHADOW_XINLINE MSHADOW_FORCE_INLINE |
| #define | MSHADOW_CINLINE MSHADOW_FORCE_INLINE |
| cpu force inline More... | |
| #define | MSHADOW_CONSTEXPR const |
| #define | MSHADOW_DEFAULT_DTYPE = ::mshadow::default_real_t |
| default data type for tensor string in code release, change it to default_real_t during development, change it to empty string so that missing template arguments can be detected More... | |
| #define | MSHADOW_USE_GLOG DMLC_USE_GLOG |
| DMLC marco for logging. More... | |
| #define | MSHADOW_THROW_EXCEPTION noexcept(false) |
| #define | MSHADOW_NO_EXCEPTION noexcept(true) |
| #define | MSHADOW_ALIGNED(x) __attribute__ ((aligned(x))) |
| #define | MSHADOW_CUDA_CALL(func) |
| Protected cuda call in mshadow. More... | |
| #define | MSHADOW_CATCH_ERROR(func) |
| Run function and catch error, log unknown error. More... | |
| #define | MSHADOW_HALF_BF_OPERATOR(RTYPE, OP) |
| #define | MSHADOW_TYPE_SWITCH(type, DType, ...) |
| #define | MSHADOW_TYPE_SWITCH_WITH_HALF2(type, DType, ...) |
| #define | MSHADOW_SGL_DBL_TYPE_SWITCH(type, DType, ...) |
| #define | MSHADOW_REAL_TYPE_SWITCH(type, DType, ...) |
| #define | MSHADOW_REAL_TYPE_SWITCH_EX(type, DType, DLargeType, ...) |
| #define | MSHADOW_LAYOUT_SWITCH(layout, Layout, ...) |
| #define | MSHADOW_IDX_TYPE_SWITCH(type, DType, ...) |
| Only supports int64 index type for aux_data in NDArray class fow now. More... | |
| #define | MSHADOW_TYPE_SWITCH_WITH_BOOL(type, DType, ...) |
Typedefs | |
| typedef int32_t | mshadow::index_t |
| type that will be used for index More... | |
| typedef index_t | mshadow::openmp_index_t |
| openmp index for linux More... | |
| typedef float | mshadow::default_real_t |
| float point type that will be used in default by mshadow More... | |
Enumerations | |
| enum | mshadow::TypeFlag { mshadow::kFloat32 = 0, mshadow::kFloat64 = 1, mshadow::kFloat16 = 2, mshadow::kUint8 = 3, mshadow::kInt32 = 4, mshadow::kInt8 = 5, mshadow::kInt64 = 6, mshadow::kBool = 7, mshadow::kInt16 = 8, mshadow::kUint16 = 9, mshadow::kUint32 = 10, mshadow::kUint64 = 11, mshadow::kBfloat16 = 12 } |
| data type flag More... | |
| enum | mshadow::LayoutFlag { mshadow::kNCHW = 0, mshadow::kNHWC, mshadow::kCHWN, mshadow::kNCW = 1 << 3, mshadow::kNWC, mshadow::kCWN, mshadow::kNCDHW = 1 << 5, mshadow::kNDHWC, mshadow::kCDHWN } |
Variables | |
| const unsigned | mshadow::kRandBufferSize = 1000000 |
| buffer size for each random number generator More... | |
| const float | mshadow::kPi = 3.1415926f |
| pi More... | |
| const int | mshadow::default_type_flag = DataType<default_real_t>::kFlag |
| type enum value for default real type More... | |
| const int | mshadow::default_layout = kNCHW |
| default layout for 4d tensor More... | |
| const int | mshadow::default_layout_5d = kNCDHW |
| default layout for 5d tensor More... | |
Macro Definition Documentation
◆ MSHADOW_ALIGNED
| #define MSHADOW_ALIGNED | ( | x | ) | __attribute__ ((aligned(x))) |
◆ MSHADOW_ALLOC_PAD
| #define MSHADOW_ALLOC_PAD true |
whether do padding during allocation
◆ MSHADOW_CATCH_ERROR
| #define MSHADOW_CATCH_ERROR | ( | func | ) |
Run function and catch error, log unknown error.
- Parameters
-
func Expression to call.
◆ MSHADOW_CINLINE
| #define MSHADOW_CINLINE MSHADOW_FORCE_INLINE |
cpu force inline
◆ MSHADOW_CONSTEXPR
| #define MSHADOW_CONSTEXPR const |
◆ MSHADOW_CUDA_CALL
| #define MSHADOW_CUDA_CALL | ( | func | ) |
Protected cuda call in mshadow.
- Parameters
-
func Expression to call. It checks for CUDA errors after invocation of the expression.
◆ MSHADOW_DEFAULT_DTYPE
| #define MSHADOW_DEFAULT_DTYPE = ::mshadow::default_real_t |
default data type for tensor string in code release, change it to default_real_t during development, change it to empty string so that missing template arguments can be detected
◆ MSHADOW_FORCE_INLINE
| #define MSHADOW_FORCE_INLINE inline __attribute__((always_inline)) |
◆ MSHADOW_FORCE_STREAM
| #define MSHADOW_FORCE_STREAM 1 |
force user to use GPU stream during computation error will be shot when default stream NULL is used
◆ MSHADOW_HALF_BF_OPERATOR
| #define MSHADOW_HALF_BF_OPERATOR | ( | RTYPE, | |
| OP | |||
| ) |
◆ MSHADOW_IDX_TYPE_SWITCH
| #define MSHADOW_IDX_TYPE_SWITCH | ( | type, | |
| DType, | |||
| ... | |||
| ) |
Only supports int64 index type for aux_data in NDArray class fow now.
◆ MSHADOW_IN_CXX11
| #define MSHADOW_IN_CXX11 0 |
macro to decide existence of c++11 compiler
◆ MSHADOW_LAYOUT_SWITCH
| #define MSHADOW_LAYOUT_SWITCH | ( | layout, | |
| Layout, | |||
| ... | |||
| ) |
◆ MSHADOW_MIN_PAD_RATIO
| #define MSHADOW_MIN_PAD_RATIO 2 |
x dimension of data must be bigger pad_size * ratio to be alloced padded memory, otherwise use tide allocation for example, if pad_ratio=2, GPU memory alignement size is 32, then we will only allocate padded memory if x dimension > 64 set it to 0 then we will always allocate padded memory
◆ MSHADOW_NO_EXCEPTION
| #define MSHADOW_NO_EXCEPTION noexcept(true) |
◆ MSHADOW_OLD_CUDA
| #define MSHADOW_OLD_CUDA 0 |
seems CUDAARCH is deprecated in future NVCC set this to 1 if you want to use CUDA version smaller than 2.0
◆ MSHADOW_REAL_TYPE_SWITCH
| #define MSHADOW_REAL_TYPE_SWITCH | ( | type, | |
| DType, | |||
| ... | |||
| ) |
◆ MSHADOW_REAL_TYPE_SWITCH_EX
| #define MSHADOW_REAL_TYPE_SWITCH_EX | ( | type, | |
| DType, | |||
| DLargeType, | |||
| ... | |||
| ) |
◆ MSHADOW_SGL_DBL_TYPE_SWITCH
| #define MSHADOW_SGL_DBL_TYPE_SWITCH | ( | type, | |
| DType, | |||
| ... | |||
| ) |
◆ MSHADOW_STAND_ALONE
| #define MSHADOW_STAND_ALONE 0 |
if this macro is define to be 1, mshadow should compile without any of other libs
◆ MSHADOW_THROW_EXCEPTION
| #define MSHADOW_THROW_EXCEPTION noexcept(false) |
◆ MSHADOW_TYPE_SWITCH
| #define MSHADOW_TYPE_SWITCH | ( | type, | |
| DType, | |||
| ... | |||
| ) |
◆ MSHADOW_TYPE_SWITCH_WITH_BOOL
| #define MSHADOW_TYPE_SWITCH_WITH_BOOL | ( | type, | |
| DType, | |||
| ... | |||
| ) |
◆ MSHADOW_TYPE_SWITCH_WITH_HALF2
| #define MSHADOW_TYPE_SWITCH_WITH_HALF2 | ( | type, | |
| DType, | |||
| ... | |||
| ) |
◆ MSHADOW_USE_CBLAS
| #define MSHADOW_USE_CBLAS 0 |
use CBLAS for CBLAS
◆ MSHADOW_USE_CUDA
| #define MSHADOW_USE_CUDA 1 |
use CUDA support, must ensure that the cuda include path is correct, or directly compile using nvcc
◆ MSHADOW_USE_CUDNN
| #define MSHADOW_USE_CUDNN 0 |
use CUDNN support, must ensure that the cudnn include path is correct
◆ MSHADOW_USE_CUSOLVER
| #define MSHADOW_USE_CUSOLVER MSHADOW_USE_CUDA |
use CUSOLVER support
◆ MSHADOW_USE_F16C
| #define MSHADOW_USE_F16C 1 |
whether use F16C instruction set architecture extension
◆ MSHADOW_USE_GLOG
| #define MSHADOW_USE_GLOG DMLC_USE_GLOG |
DMLC marco for logging.
◆ MSHADOW_USE_MKL
| #define MSHADOW_USE_MKL 1 |
use MKL for BLAS
◆ MSHADOW_USE_NVML
| #define MSHADOW_USE_NVML 0 |
whether use NVML to get dynamic info
◆ MSHADOW_USE_SSE
| #define MSHADOW_USE_SSE 1 |
whether use SSE
◆ MSHADOW_XINLINE
| #define MSHADOW_XINLINE MSHADOW_FORCE_INLINE |
