Quantize with MKL-DNN backend¶
This document is to introduce how to quantize the customer models from FP32 to INT8 with Apache/MXNet toolkit and APIs under Intel CPU.
If you are not familiar with Apache/MXNet quantization flow, please reference quantization blog first, and the performance data is shown in Apache/MXNet C++ interface and GluonCV.
Installation and Prerequisites¶
Installing MXNet with MKLDNN backend is an easy and essential process. You can follow How to build and install MXNet with MKL-DNN backend to build and install MXNet from source. Also, you can install the release or nightly version via PyPi and pip directly by running:
# release version
pip install mxnet-mkl
# nightly version
pip install mxnet-mkl --pre
Image Classification Demo¶
A quantization script imagenet_gen_qsym_mkldnn.py has been designed to launch quantization for image-classification models. This script is integrated with Gluon-CV modelzoo, so that all pre-trained models can be downloaded from Gluon-CV and then converted for quantization. For details, you can refer Model Quantization with Calibration Examples.
Integrate Quantization Flow to Your Project¶
Quantization flow works for both symbolic and Gluon models. If you’re using Gluon, you can first refer Saving and Loading Gluon Models to hybridize your computation graph and export it as a symbol before running quantization.
In general, the quantization flow includes 4 steps. The user can get the acceptable accuracy from step 1 to 3 with minimum effort. Most of thing in this stage is out-of-box and the data scientists and researchers only need to focus on how to represent data and layers in their model. After a quantized model is generated, you may want to deploy it online and the performance will be the next key point. Thus, step 4, calibration, can improve the performance a lot by reducing lots of runtime calculation.

Now, we are going to take Gluon ResNet18 as an example to show how each step work.
Initialize Model¶
import logging
import mxnet as mx
from mxnet.gluon.model_zoo import vision
from mxnet.contrib.quantization import *
logging.basicConfig()
logger = logging.getLogger('logger')
logger.setLevel(logging.INFO)
batch_shape = (1, 3, 224, 224)
resnet18 = vision.resnet18_v1(pretrained=True)
resnet18.hybridize()
resnet18.forward(mx.nd.zeros(batch_shape))
resnet18.export('resnet18_v1')
sym, arg_params, aux_params = mx.model.load_checkpoint('resnet18_v1', 0)
# (optional) visualize float32 model
mx.viz.plot_network(sym)
First, we download resnet18-v1 model from gluon modelzoo and export it as a symbol. You can visualize float32 model. Below is a raw residual block.
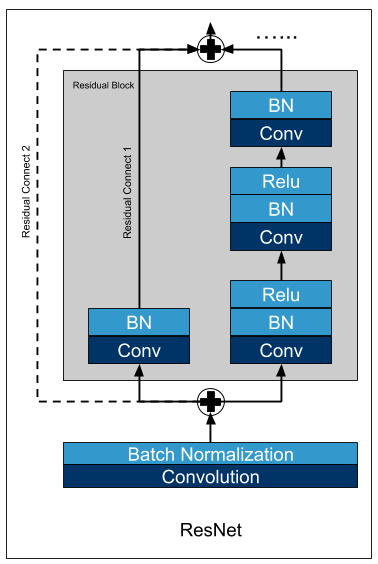
Model Fusion¶
sym = sym.get_backend_symbol('MKLDNN_QUANTIZE')
# (optional) visualize fused float32 model
mx.viz.plot_network(sym)
It’s important to add this line to enable graph fusion before quantization to get better performance. Below is a fused residual block. Batchnorm, Activation and elemwise_add are fused into Convolution.
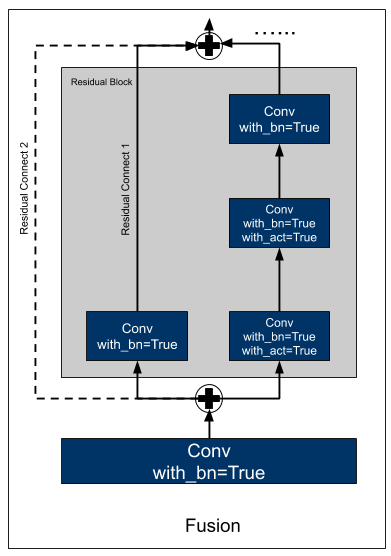
Quantize Model¶
A python interface quantize_graph is provided for the user. Thus, it is very flexible for the data scientist to construct the expected models based on different requirements in a real deployment.
# quantize configs
# set exclude layers
excluded_names = []
# set calib mode.
calib_mode = 'none'
# set calib_layer
calib_layer = None
# set quantized_dtype
quantized_dtype = 'auto'
logger.info('Quantizing FP32 model Resnet18-V1')
qsym, qarg_params, aux_params, collector = quantize_graph(sym=sym, arg_params=arg_params, aux_params=aux_params,
excluded_sym_names=excluded_names,
calib_mode=calib_mode, calib_layer=calib_layer,
quantized_dtype=quantized_dtype, logger=logger)
# (optional) visualize quantized model
mx.viz.plot_network(qsym)
# save quantized model
mx.model.save_checkpoint('quantized-resnet18_v1', 0, qsym, qarg_params, aux_params)
By applying quantize_graph to the symbolic model, a new quantized model can be generated, named qsym along with its parameters. We can see _contrib_requantize operators are inserted after Convolution to convert the INT32 output to FP32.
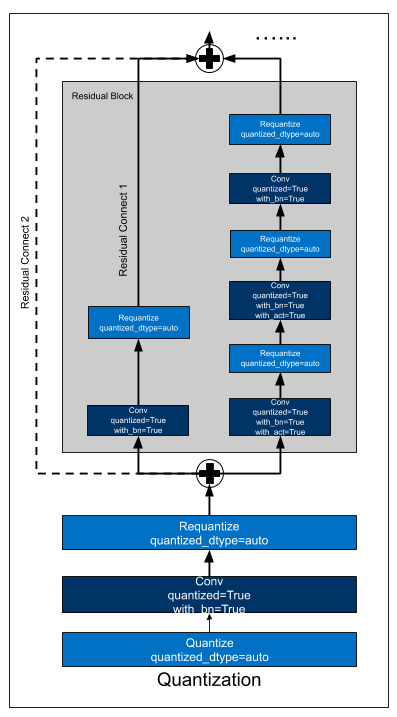
Below table gives some descriptions.
param |
type |
description |
|---|---|---|
excluded _sym_names |
list of strings |
A list of strings representing the names of the symbols that users want to excluding from being quantized. |
calib_mode |
str |
If calib_mode=‘none’, no calibration will be used and the thresholds for requantization after the corresponding layers will be calculated at runtime by calling min and max operators. The quantized models generated in this mode are normally 10-20% slower than those with calibrations during inference.If calib_mode=‘naive’, the min and max values of the layer outputs from a calibration dataset will be directly taken as the thresholds for quantization.If calib_mode=‘entropy’, the thresholds for quantization will be derived such that the KL divergence between the distributions of FP32 layer outputs and quantized layer outputs is minimized based upon the calibration dataset. |
c alib_layer |
function |
Given a layer’s output name in string, return True or False for deciding whether to calibrate this layer.If yes, the statistics of the layer’s output will be collected; otherwise, no information of the layer’s output will be collected.If not provided, all the layers’ outputs that need requantization will be collected. |
quant ized_dtype |
str |
The quantized destination type for input data. Currently support ‘int8’, ‘uint8’ and ‘auto’.‘auto’ means automatically select output type according to calibration result. |
Evaluate & Tune¶
Now, you get a pair of quantized symbol and params file for inference. For Gluon inference, only difference is to load model and params by a SymbolBlock as below example:
quantized_net = mx.gluon.SymbolBlock.imports('quantized-resnet18_v1-symbol.json', 'data', 'quantized-resnet18_v1-0000.params')
quantized_net.hybridize(static_shape=True, static_alloc=True)
batch_size = 1
data = mx.nd.ones((batch_size,3,224,224))
quantized_net(data)
Now, you can get the accuracy from a quantized network. Furthermore, you can try to select different layers or OPs to be quantized by excluded_sym_names parameter and figure out an acceptable accuracy.
Calibrate Model (optional for performance)¶
The quantized model generated in previous steps can be very slow during inference since it will calculate min and max at runtime. We recommend using offline calibration for better performance by setting calib_mode to naive or entropy. And then calling set_monitor_callback api to collect layer information with a subset of the validation datasets before int8 inference.
# quantization configs
# set exclude layers
excluded_names = []
# set calib mode.
calib_mode = 'naive'
# set calib_layer
calib_layer = None
# set quantized_dtype
quantized_dtype = 'auto'
logger.info('Quantizing FP32 model resnet18-V1')
cqsym, cqarg_params, aux_params, collector = quantize_graph(sym=sym, arg_params=arg_params, aux_params=aux_params,
excluded_sym_names=excluded_names,
calib_mode=calib_mode, calib_layer=calib_layer,
quantized_dtype=quantized_dtype, logger=logger)
# download imagenet validation dataset
mx.test_utils.download('https://data.mxnet.io/data/val_256_q90.rec', 'dataset.rec')
# set rgb info for data
mean_std = {'mean_r': 123.68, 'mean_g': 116.779, 'mean_b': 103.939, 'std_r': 58.393, 'std_g': 57.12, 'std_b': 57.375}
# set batch size
batch_size = 16
# create DataIter
data = mx.io.ImageRecordIter(path_imgrec='dataset.rec', batch_size=batch_size, data_shape=batch_shape[1:], rand_crop=False, rand_mirror=False, **mean_std)
# create module
mod = mx.mod.Module(symbol=sym, label_names=None, context=mx.cpu())
mod.bind(for_training=False, data_shapes=data.provide_data, label_shapes=None)
mod.set_params(arg_params, aux_params)
# calibration configs
# set num_calib_batches
num_calib_batches = 5
max_num_examples = num_calib_batches * batch_size
# monitor FP32 Inference
mod._exec_group.execs[0].set_monitor_callback(collector.collect, monitor_all=True)
num_batches = 0
num_examples = 0
for batch in data:
mod.forward(data_batch=batch, is_train=False)
num_batches += 1
num_examples += batch_size
if num_examples >= max_num_examples:
break
if logger is not None:
logger.info("Collected statistics from %d batches with batch_size=%d"
% (num_batches, batch_size))
After that, layer information will be filled into the collector returned by quantize_graph api. Then, you need to write the layer information into int8 model by calling calib_graph api.
# write scaling factor into quantized symbol
cqsym, cqarg_params, aux_params = calib_graph(qsym=cqsym, arg_params=arg_params, aux_params=aux_params,
collector=collector, calib_mode=calib_mode,
quantized_dtype=quantized_dtype, logger=logger)
# (optional) visualize quantized model
mx.viz.plot_network(cqsym)
Below is a quantized residual block with naive calibration. We can see min_calib_range and max_calib_range are written into _contrib_requantize operators.
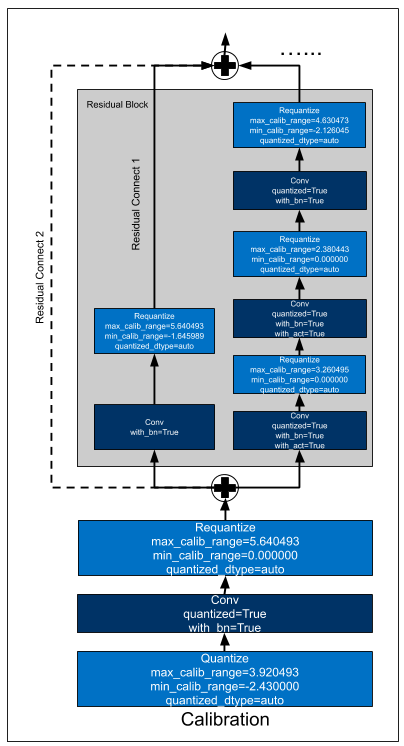
When you get a quantized model with calibration, keeping sure to call fusion api again since this can fuse some requantize or dequantize operators for further performance improvement.
# perform post-quantization fusion
cqsym = cqsym.get_backend_symbol('MKLDNN_QUANTIZE')
# (optional) visualize post-quantized model
mx.viz.plot_network(cqsym)
# save quantized model
mx.model.save_checkpoint('quantized-resnet18_v1', 0, cqsym, cqarg_params, aux_params)
Below is a post-quantized residual block. We can see _contrib_requantize operators are fused into Convolution operators.

BTW, You can also modify the min_calib_range and max_calib_range in the JSON file directly.
{
"op": "_sg_mkldnn_conv",
"name": "quantized_sg_mkldnn_conv_bn_act_6",
"attrs": {
"max_calib_range": "3.562147",
"min_calib_range": "0.000000",
"quantized": "true",
"with_act": "true",
"with_bn": "true"
},
......
Tips for Model Calibration¶
Accuracy Tuning¶
Try to use
entropycalib mode;Try to exclude some layers which may cause obvious accuracy drop;
Change calibration dataset by setting different
num_calib_batchesor shuffle your validation dataset;
Performance Tuning¶
Keep sure to perform graph fusion before quantization;
If lots of
requantizelayers exist, keep sure to perform post-quantization fusion after calibration;Compare the MXNet profile or
MKLDNN_VERBOSEof float32 and int8 inference;
Deploy with Python/C++¶
MXNet also supports deploy quantized models with C++. Refer MXNet C++ Package for more details.