Float16
Mixed precision training using float16
In this tutorial we will walk through how one can train deep learning neural networks with mixed precision on supported hardware. We will first see how to use float16 (both with Gluon and Symbolic APIs) and then some techniques on achieving good performance and accuracy.
Background
The computational resources required for training deep neural networks have been lately increasing because of growing complexity and model size. Mixed precision training allows us to reduce the utilization of the resources by using lower precision arithmetic which is computationally less expensive and less costly in terms of space utilization. In this approach you can train using 16 bit floating point (half precision) while using 32 bit floating point (single precision) for output buffers of float16 computation. This allows one to achieve the same accuracy as training with single precision, while decreasing the required memory and training or inference time.
The float16 data type is a 16 bit floating point representation according to the IEEE 754 standard. It has a dynamic range where the precision can go from 0.0000000596046 (highest, for values closest to 0) to 32 (lowest, for values in the range 32768-65536). Despite the inherent reduced precision when compared to single precision float (float32), using float16 has many advantages. The most obvious advantages are that you can reduce the size of the model by half allowing the training of larger models and using larger batch sizes. The reduced memory footprint also helps in reducing the pressure on memory bandwidth and lowering communication costs. On hardware with specialized support for float16 computation you can also greatly improve the speed of training and inference. The Volta range of Graphics Processing Units (GPUs) from Nvidia have Tensor Cores which perform efficient float16 computation. A tensor core allows accumulation of half precision products into single or half precision outputs. For the rest of this tutorial we assume that we are working with Nvidia's Tensor Cores on a Volta GPU.
Prerequisites
- Volta range of Nvidia GPUs (e.g. AWS P3 instance)
- CUDA 9 or higher
- cuDNN v7 or higher
This tutorial also assumes understanding of how to train a network with float32 (the default). Please refer to logistic regression tutorial to get started with Apache MXNet and Gluon API. This tutorial focuses on the changes needed to switch from float32 to mixed precision and tips on achieving the best performance with mixed precision.
Using the Gluon API
Training or Inference
With Gluon API, you need to take care of three things to convert a model to support computation with float16.
- Cast Gluon
Block's parameters and expected input type to float16 by calling the cast method of theBlockrepresenting the network.
net.cast('float16')
- Ensure the data input to the network is of float16 type. If your
DataLoaderorIteratorproduces output in another datatype, then you would have to cast your data. There are different ways you can do this. The easiest would be to use the astype method of NDArrays.
data = data.astype('float16', copy=False)
If you are using images and DataLoader, you can also use a Cast transform.
- It is preferable to use multi_precision mode of optimizer when training in float16. This mode of optimizer maintains a master copy of the weights in float32 even when the training (i.e. forward and backward pass) is in float16. This helps increase precision of the weight updates and can lead to faster convergence in some scenarios.
optimizer = mx.optimizer.create('sgd', multi_precision=True, lr=0.01)
You can play around with mixed precision using the image classification example. We suggest using the Caltech101 dataset option in that example and using a ResNet50V1 network so you can quickly see the performance improvement and how the accuracy is unaffected. Here's the starter command to run this example.
python image_classification.py --model resnet50_v1 --dataset caltech101 --gpus 0 --num-worker 30 --dtype float16
Fine-tuning
You can also fine-tune a model, which was originally trained in float32, to use float16. Below is an example of how to fine-tune a pretrained model from the Model Zoo. You would first need to fetch the pretrained network and then cast that network to float16.
import numpy as np
import mxnet as mx
from mxnet.gluon.model_zoo.vision import get_model
pretrained_net = get_model(name='resnet50_v2', ctx=mx.cpu(),
pretrained=True, classes=1000)
pretrained_net.cast('float16')
Then, if you have another Resnet50V2 model you want to fine-tune, you can just assign the features to that network and then cast it.
net = get_model(name='resnet50_v2', ctx=mx.cpu(),
pretrained=False, classes=101)
net.collect_params().initialize(mx.init.Xavier(magnitude=2.24), ctx=mx.cpu())
net.features = pretrained_net.features
net.cast('float16')
You can check the parameters of the model by calling summary with some fake data. Notice the provided dtype=np.float16 in the line below. As it was mentioned earlier, we have to provide data as float16 as well.
net.summary(mx.nd.uniform(shape=(1, 3, 224, 224), dtype=np.float16))
Using the Symbolic API
Training a network in float16 with the Symbolic API involves the following steps.
- Add a layer at the beginning of the network, to cast the data to float16. This will ensure that all the following layers compute in float16.
- It is advisable to cast the output of the layers before softmax to float32, so that the softmax computation is done in float32. This is because softmax involves large reductions and it helps to keep that in float32 for more precise answer.
- It is advisable to use the multi-precision mode of the optimizer for more precise weight updates. Here's how you would enable this mode when creating an optimizer.
optimizer = mx.optimizer.create('sgd', multi_precision=True, lr=0.01)
For a full example, please refer to resnet.py file on GitHub. A small, relevant excerpt from that file is presented below.
data = mx.sym.Variable(name="data")
if dtype == 'float16':
data = mx.sym.Cast(data=data, dtype=np.float16)
# ... the rest of the network
net_out = net(data)
if dtype == 'float16':
net_out = mx.sym.Cast(data=net_out, dtype=np.float32)
output = mx.sym.SoftmaxOutput(data=net_out, name='softmax')
If you would like to train ResNet50 model on ImageNet using float16 precision, you can find the full script here
If you don't have ImageNet dataset at your disposal, you can still run the script above using synthetic float16 data by providing the following command:
python train_imagenet.py --network resnet-v1 --num-layers 50 --benchmark 1 --gpus 0 --batch-size 256 --dtype float16
There's a similar example for float16 fine tuning here of selected models: Inception v3, Inception v4, ResNetV1, ResNet50, ResNext or VGG. The command below shows how to use that script to fine-tune a Resnet50 model trained on Imagenet for the Caltech 256 dataset using float16.
python fine-tune.py --network resnet --num-layers 50 --pretrained-model imagenet1k-resnet-50 --data-train ~/.mxnet/dataset/caltech-256/caltech256-train.rec --data-val ~/data/caltech-256/caltech256-val.rec --num-examples 15420 --num-classes 256 --gpus 0 --batch-size 64 --dtype float16
If you don't have the Caltech256 dataset, you can download it using the script below, and convert it into .rec file format using im2rec utility file
import os
from os.path import expanduser
import tarfile
import mxnet as mx
data_folder = expanduser("~/.mxnet/datasets/")
dataset_name = "256_ObjectCategories"
archive_file = "{}.tar".format(dataset_name)
archive_path = os.path.join(data_folder, archive_file)
data_url = "http://www.vision.caltech.edu/Image_Datasets/Caltech256/"
if not os.path.isfile(archive_path):
mx.test_utils.download("{}{}".format(data_url, archive_file),
dirname=data_folder)
print('Extracting {} in {}...'.format(archive_file, data_folder))
tar = tarfile.open(archive_path)
tar.extractall(data_folder)
tar.close()
print('Data extracted.')
Example training results
Let us consider training a Resnet50V1 model on the ImageNet 2012 dataset. For this model, the GPU memory usage is close to the capacity of V100 GPU with a batch size of 128 when using float32. Using float16 allows the use of 256 batch size. Shared below are results using 8 V100 GPUs on a an AWS p3.16xlarge instance.
Let us compare the three scenarios that arise here: float32 with 1024 batch size, float16 with 1024 batch size and float16 with 2048 batch size. These jobs trained for 90 epochs using a learning rate of 0.4 for 1024 batch size and 0.8 for 2048 batch size. This learning rate was decayed by a factor of 0.1 at the 30th, 60th and 80th epochs. The only changes made for the float16 jobs when compared to the float32 job were that the network and data were cast to float16, and the multi-precision mode was used for optimizer. The final accuracy at 90th epoch and the time to train are tabulated below for these three scenarios. The top-1 validation errors at the end of each epoch are also plotted below.
| Batch size | Data type | Top 1 Validation accuracy | Time to train | Speedup |
|---|---|---|---|---|
| 1024 | float32 | 76.18% | 11.8 hrs | 1 |
| 1024 | float16 | 76.34% | 7.3 hrs | 1.62x |
| 2048 | float16 | 76.29% | 6.5 hrs | 1.82x |
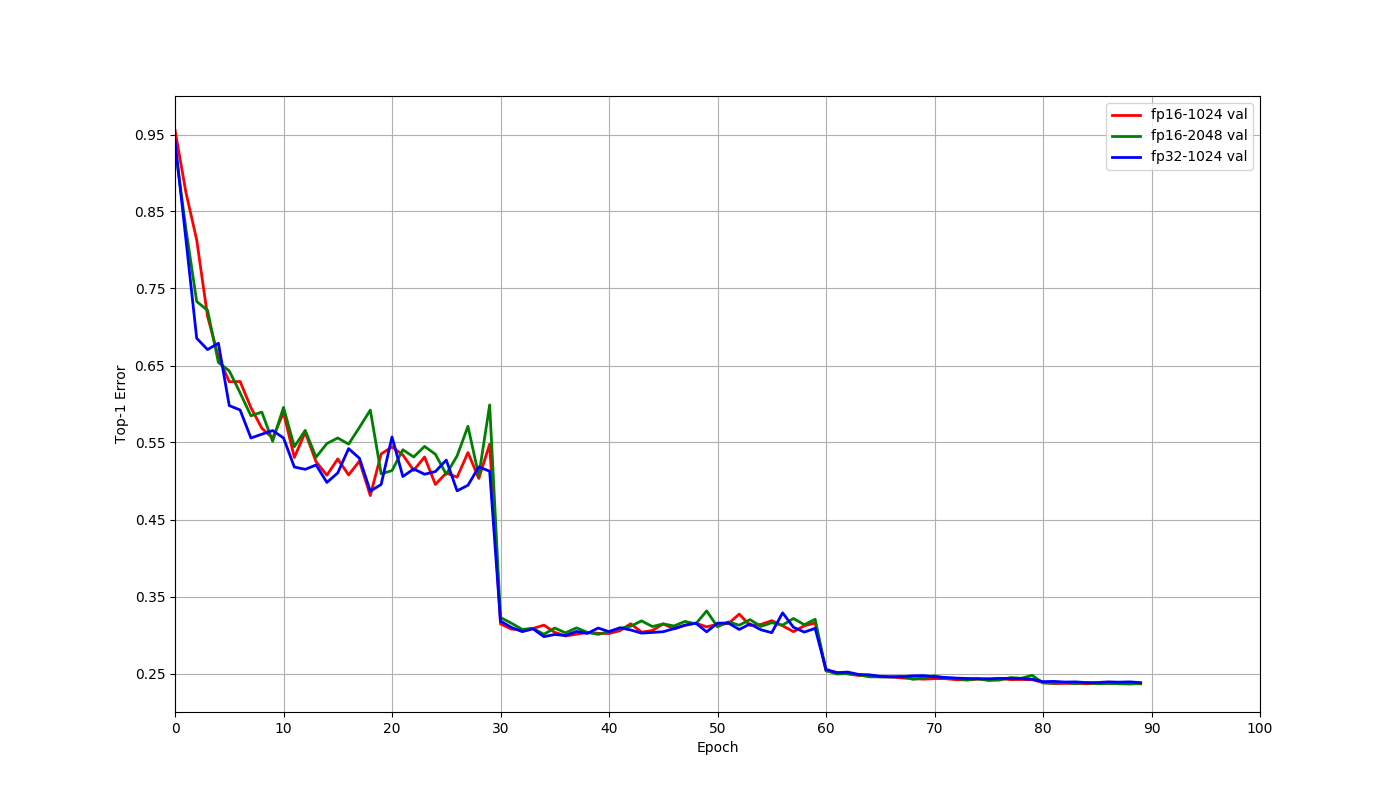
The difference in accuracies above are within normal random variation, and there is no reason to expect float16 to have better accuracy than float32 in general. As the plot indicates, training behaves similarly for these cases, even though we didn't have to change any other hyperparameters. We can also see from the table that using float16 helps train faster through faster computation with float16 as well as allowing the use of larger batch sizes.
Things to keep in mind
For performance
Typical performance gains seen for float16 typically range 1.6x-2x for convolutional networks like Resnet and even about 3x for networks with LSTMs. The performance gain you see can depend on certain things which this section will introduce.
Nvidia Tensor Cores essentially perform the computation
D = A * B + C, where A and B are half precision matrices, while C and D could be either half precision or full precision. The tensor cores are most efficient when dimensions of these matrices are multiples of 8. This means that Tensor Cores can not be used in all cases for fast float16 computation. When training models like Resnet50 on the Cifar10 dataset, the tensors involved are sometimes smaller, and Tensor Cores can not always be used. The computation in that case falls back to slower algorithms and using float16 turns out to be slower than float32 on a single GPU. Note that when using multiple GPUs, using float16 can still be faster than float32 because of reduction in communication costs.When you scale up the batch size ensure that IO and data pre-processing is not your bottleneck. If you see a slowdown this would be the first thing to check.
It is advisable to use batch sizes that are multiples of 8 because of the above reason when training with float16. As always, batch sizes which are powers of 2 would be best when compared to those around it.
You can check whether your program is using Tensor cores for fast float16 computation by profiling with
nvprof. The operations withs884cudnnin their names represent the use of Tensor cores.When not limited by GPU memory, it can help to set the environment variable
MXNET_CUDNN_AUTOTUNE_DEFAULTto2. This configures MXNet to run tuning tests and choose the fastest convolution algorithm whose memory requirements may exceed the default memory of CUDA workspace.Please note that float16 on CPU might not be supported for all operators, as in most cases float16 on CPU is much slower than float32.
For accuracy
Multi precision mode
When training in float16, it is advisable to still store the master copy of the weights in float32 for better accuracy. The higher precision of float32 helps overcome cases where gradient update can become 0 if represented in float16. This mode can be activated by setting the parameter multi_precision of optimizer params to True as in the above example. It has been found that this is not required for all networks to achieve the same accuracy as with float32, but nevertheless recommended. Note that for distributed training, this is currently slightly slower than without multi_precision, but still much faster than using float32 for training.
Large reductions
Since float16 has low precision for large numbers, it is best to leave layers which perform large reductions in float32. This includes BatchNorm and Softmax. Ensuring that Batchnorm performs reduction in float32 is handled by default in both Gluon and Module APIs. While Softmax is set to use float32 even during float16 training in Gluon, in the Module API it needs to be a cast to float32 before softmax as the above symbolic example code shows.
Loss scaling
For some networks just switching the training to float16 mode was not found to be enough to reach the same accuracy as when training with float32. This is because the activation gradients computed are too small and could not be represented in float16 representable range. Such networks can be made to achieve the accuracy reached by float32 with a couple of changes.
Most of the float16 representable range is not used by activation gradients generally. So you can shift the gradients into float16 range by scaling up the loss by a factor S. By the chain rule, this scales up the loss before backward pass, and then you can scale back the gradients before updating the weights. This ensures that training in float16 can use the same hyperparameters as used during float32 training.
Here's how you can configure the loss to be scaled up by 128 and rescale the gradient down before updating the weights.
Gluon API
loss = gluon.loss.SoftmaxCrossEntropyLoss(weight=128)
optimizer = mx.optimizer.create('sgd',
multi_precision=True,
rescale_grad=1.0/128)
Module API
mxnet.sym.SoftmaxOutput(other_args, grad_scale=128.0)
optimizer = mx.optimizer.create('sgd',
multi_precision=True,
rescale_grad=1.0/128)
Networks like Multibox SSD, R-CNN, bigLSTM and Seq2seq were found to exhibit such behavior. You can choose a constant scaling factor while ensuring that the absolute value of gradient when multiplied by this factor remains in the range of float16. Generally powers of 2 like 64, 128, 256, 512 are chosen. Refer to the linked articles below for more details on this.
References
- Training with Mixed Precision User Guide
- Mixed Precision Training at ICLR 2018
- Mixed-Precision Training of Deep Neural Networks
Recommended Next Steps
- Check out our video tutorial on Using Mixed Precision with MXNet