Activation Blocks¶
Deep neural networks are a way to express a nonlinear function with lots of parameters from input data to outputs. The nonlinearities that allow neural networks to capture complex patterns in data are referred to as activation functions. Over the course of the development of neural networks, several nonlinear activation functions have been introduced to make gradient-based deep learning tractable.
If you are looking to answer the question, ‘which activation function should I use for my neural network model?’, you should probably go with ReLU. Unless you’re trying to implement something like a gating mechanism, like in LSTMs or GRU cells, then you should opt for sigmoid and/or tanh in those cells. However, if you have a working model architecture and you’re trying to improve its performance by swapping out activation functions or treating the activation function as a hyperparameter, then you may want to try hand-designed activations like SELU, SiLU, or GELU. This guide describes these activation functions and others implemented in MXNet in detail.
Visualizing Activations¶
In order to compare the various activation functions and to understand the nuances of their differences we have a snippet of code to plot the activation functions (used in the forward pass) and their gradients (used in the backward pass).
[1]:
import numpy as np
import mxnet as mx
from matplotlib import pyplot as plt
%matplotlib inline
def visualize_activation(activation_fn):
data = np.linspace(-10, 10, 501)
x = mx.np.array(data)
x.attach_grad()
with mx.autograd.record():
y = activation_fn(x)
y.backward()
plt.figure()
plt.plot(data, y.asnumpy())
plt.plot(data, x.grad.asnumpy())
activation = activation_fn.__class__.__name__[:-1]
plt.legend(["{} activation".format(activation), "{} gradient".format(activation)])
Sigmoids¶
Sigmoid¶
The sigmoid activation function, also known as the logistic function or logit function, is perhaps the most widely known activation owing to its long history in neural network training and appearance in logistic regression and kernel methods for classification.
The sigmoid activation is a non-linear function that transforms any real valued input to a value between 0 and 1, giving it a natural probabilistic interpretation. The sigmoid takes the form of the function below.
or alternatively
Warning: the term sigmoid is overloaded and can be used to refer to the class of ‘s’ shaped functions or particularly to the logistic function that we’ve just described. In MxNet the sigmoid activation specifically refers to logistic function sigmoid.
[2]:
visualize_activation(mx.gluon.nn.Activation('sigmoid'))
[04:45:43] /work/mxnet/src/storage/storage.cc:202: Using Pooled (Naive) StorageManager for CPU
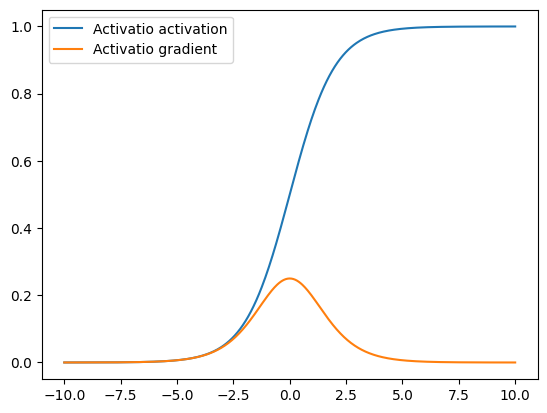
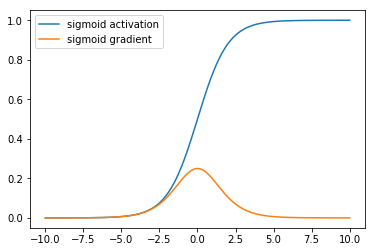
The sigmoid activation has since fallen out of use as the preferred activation function in designing neural networks due to some of its properties, shown in the plot above, like not being zero-centered and inducing vanishing gradients, that leads to poor performance during neural network training. Vanishing gradients here refers to the tendency of the gradient of the sigmoid function to be nearly zero for most input values.
tanh¶
The tanh, or hyperbolic tangent, activation function is also an s shaped curve albeit one whose output values range from -1 to 1. It is defined by the mathematical equation:
tanh addresses the issues of not being zero centered associated with the sigmoid activation function but still retains the vanishing gradient problems due to the gradient being asymptotically zero for values outside a narrow range of inputs.
In fact, the tanh can be rewritten as,
which shows its direct relation to sigmoid by the following equation:
[3]:
visualize_activation(mx.gluon.nn.Activation('tanh'))
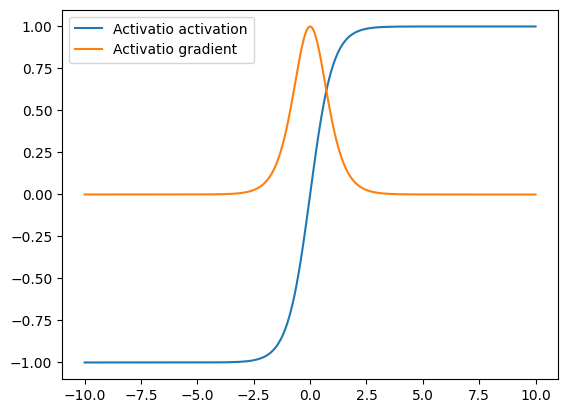
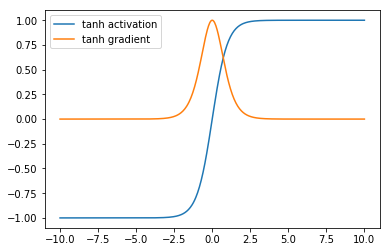
The use of tanh as activation functions in place of the logistic function was popularized by the success of the LeNet architecture and the methods paper by LeCun et al.
SoftSign¶
The SoftSign activation is an alternative to tanh that is also centered at zero but converges asymptotically to -1 and 1 polynomially instead of exponentially. This means that the SoftSign activation does not saturate as quickly as tanh. As such, there are a greater range of input values for which the softsign assigns an output of strictly between -1 and 1.
[4]:
visualize_activation(mx.gluon.nn.Activation('softsign'))
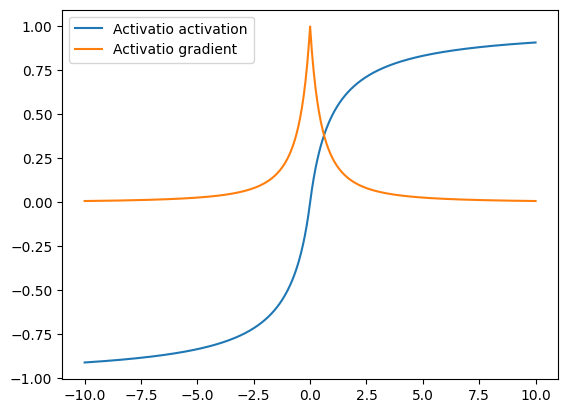
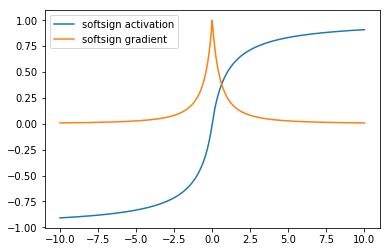
The softsign function is not a commonly used activation with most neural networks and still suffers from the vanishing gradient problem as seen in the graph above.
Rectifiers¶
ReLU¶
ReLU, or Rectified Linear Unit is the most common activation function in convolutional neural networks and introduces a simple nonlinearity. When the value of the input into ReLU is positive, then it retains the same value. When the value is negative then it becomes zero. In equation form, the ReLU function is given as:
ReLU was introduced to neural networks in the paper by Hahnloser et al and gained widespread popularity after it was shown in the paper by Alex Krizhevsky et al to perform much better than sigmoid and tanh. This paper also introduced the AlexNet CNN that won the ILSVRC challenge in 2012.
ReLU is the most widely used activation due to its simplicity and performance across multiple datasets and although there have been efforts to introduce activation functions, many of them described in this tutorial, that improve on ReLU, they have not gained as much widespread adoption.
[5]:
visualize_activation(mx.gluon.nn.Activation('relu'))
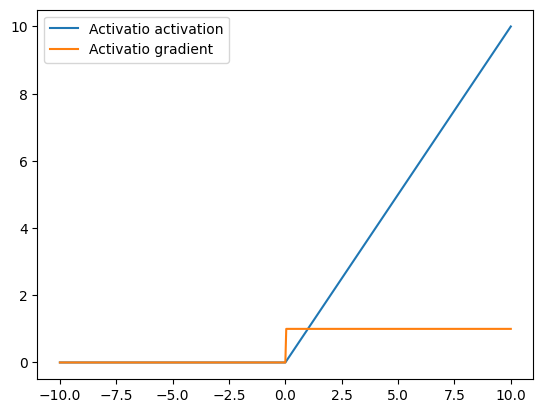
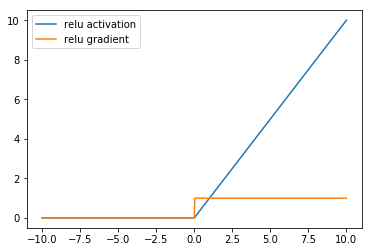
As shown above, the ReLU activation mitigates the vanishing gradient problem associated with the sigmoid family of activations, by having a larger (infinite) range of values where its gradient is non-zero. However, one drawback of ReLU as an activation function is a phenomenon referred to as the ‘Dying ReLU’, where gradient-based parameter updates can happen in such a way that the gradient flowing through a ReLU unit is always zero and the connection is never activated. This can largely be addressed by ensuring that the tuning the learning rate to ensure that it’s not set too large when training ReLU networks.
SoftReLU¶
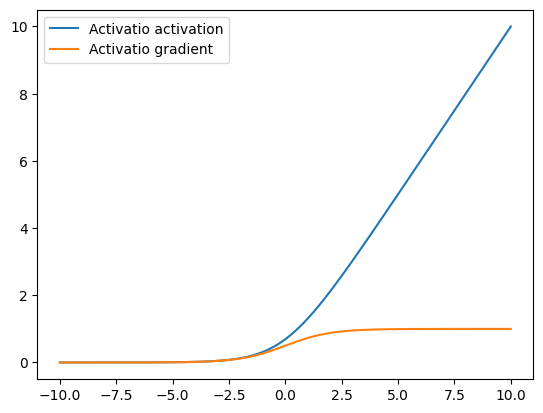
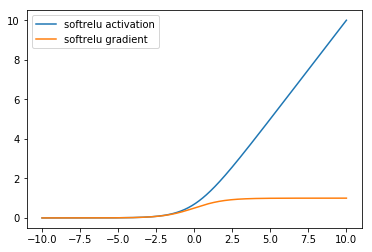
SoftReLU also known as SmoothReLU or SoftPlus is a nonlinear activation function that takes the form
The SoftReLU can be seen as a smooth version of the ReLU by observing that its derivative is the sigmoid, seen below, which is a smooth version of the gradient of the ReLU shown above.
[6]:
visualize_activation(mx.gluon.nn.Activation('softrelu'))
Leaky ReLU¶
Leaky ReLUs are a variant of ReLU that multiply the input by a small positive parameter \(\alpha\) when the value is negative. Unlike the ReLU which sets the activation and gradient for negative values to zero, the LeakyReLU allows a small gradient. The equation for the LeakyReLU is:
where \(\alpha > 0\) is small positive number. In MXNet, by default the \(\alpha\) parameter is set to 0.01.
Here is a visualization for the LeakyReLU with \(\alpha = 0.05\)
[7]:
visualize_activation(mx.gluon.nn.LeakyReLU(0.05))
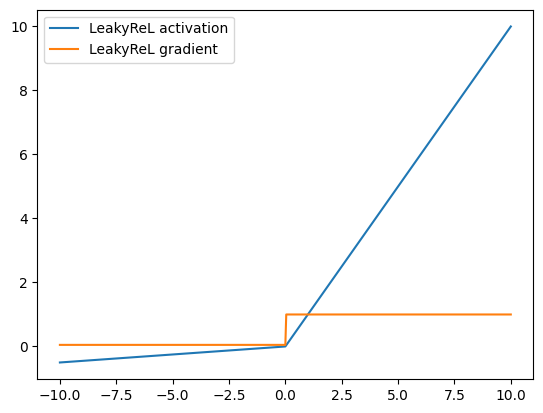
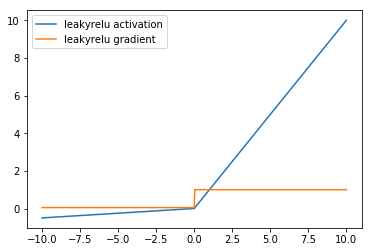
As shown in the graph, the LeakyReLU’s gradient is non-zero everywhere, in an attempt to address the ReLU’s gradient being zero for all negative values.
PReLU¶
The PReLU activation function, or Parametric Leaky ReLU introduced by He et al, is a version of LeakyReLU that learns the parameter \(\alpha\) during training. An initialization parameter is passed into the PreLU activation layer and this is treated as a learnable parameter that is updated via gradient descent during training. This is in contrast to LeakyReLU where \(\alpha\) is a hyperparameter.
[8]:
prelu = mx.gluon.nn.PReLU(mx.init.Normal(0.05))
prelu.initialize()
visualize_activation(prelu)
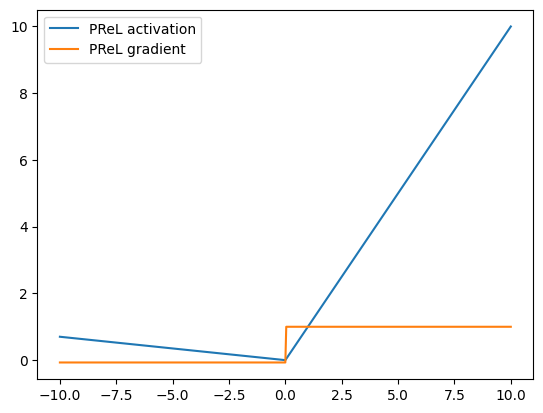
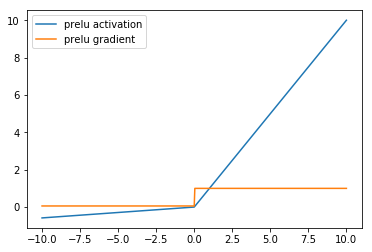
The activation function and activation gradient of PReLU have the same shape as LeakyRELU.
ELU¶
The ELU or exponential linear unit introduced by Clevert et al also addresses the vanishing gradient problem like ReLU and its variants but unlike the ReLU family, ELU allows negative values which may allow them to push mean unit activations closer to zero like batch normalization.
The ELU function has the form
[9]:
visualize_activation(mx.gluon.nn.ELU())
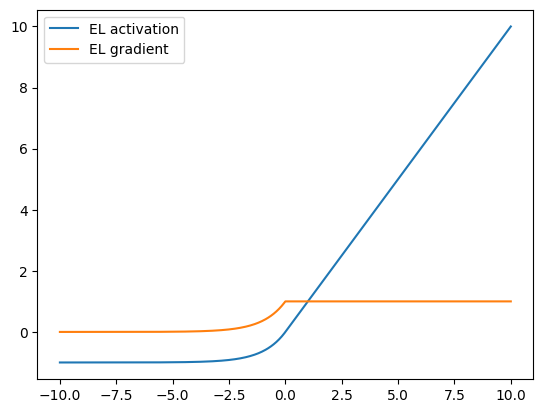
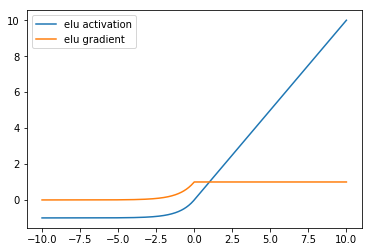
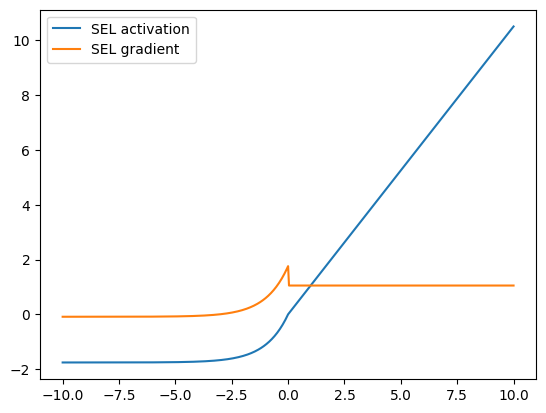
SELU¶
SELU stands for Scaled Exponential Linear Unit and was introduced by Klambuer et al and is a modification of the ELU that improves the normalization of its outputs towards a zero mean and unit variance.
The SELU function has the form
In SELU, unlike ELU, the parameters \(\alpha\) and \(\lambda\) are fixed parameters calculated from the data. For standard scaled inputs, these values are
as calculated in the paper.
[10]:
visualize_activation(mx.gluon.nn.SELU())
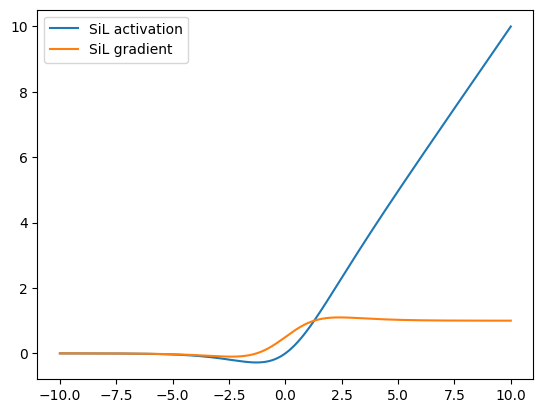
SiLU¶
The SiLU is an activation function that attempts to address the shortcomings of ReLU by combining ideas from ReLU and sigmoid. The SiLU serves as a smooth approximation to the ReLU and was originally introduced in Hendrycks et al.
The silu function is given as
where \(\sigma\) is the sigmoid activation function \(\sigma(x) = \frac{1}{1 + e^{-x}}\) described above.
[11]:
visualize_activation(mx.gluon.nn.SiLU())
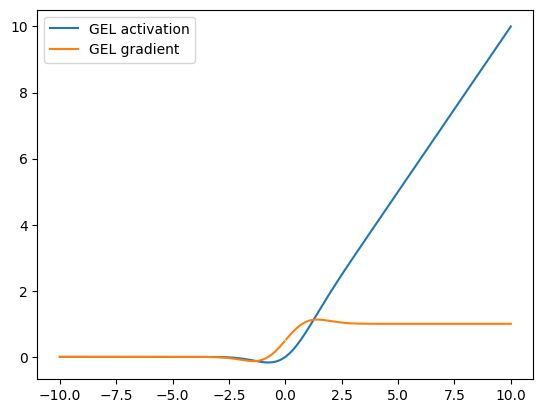
GELU¶
The GELU is a smooth approximation to the ReLU and was introduced in Hendrycks et al. It is a common activation function in architectures such as Transformers, BERT, and GPT.
The gelu function is given as
whereas the ReLU can be written as \(x\cdot\mathbf{1}(x>0)\), so \(Phi(x)\) serves as a smooth approximation to the ReLU’s indicator function.
Note \(\Phi(x) = \frac{1}{\sqrt{2 \pi}} \exp\left\{-\frac{x^2}{2}\right\}\) is the standard normal cumulative distribution.
[12]:
visualize_activation(mx.gluon.nn.GELU())
Summary¶
Activation functions introduce non-linearities to deep neural network that allow the models to capture complex interactions between features of the data.
ReLU is the activation function that is commonly used in many neural network architectures because of its simplicity and performance.
Sigmoids like the logistic (sigmoid) function and tanh where the first kinds of activation functions used in neural networks. They have since fallen out of use because of their tendency to saturate and have vanishing gradients.
Rectifiers like ReLU do not saturate like the Sigmoids and so address the vanishing gradient problem making them the de facto activation functions. ReLU however is still plagued by the dying ReLU problem.
LeakyReLU and PReLU are two similar approaches to improve ReLU and address the dying ReLU by introducing a parameter \(\alpha\) (learned in PReLU) that leaks to the gradient of negative inputs
MXNet also implements custom state-of-the-art activations like ELU, SELU, SiLU, and GELU.
Next Steps¶
Activations are just one component of neural network architectures. Here are a few MXNet resources to learn more about activation functions and how they they combine with other components of neural nets. * Learn how to create a Neural Network with these activation layers and other neural network layers in the Gluon crash course. * Check out the guide to MXNet gluon layers and blocks to learn about the other neural network layers in implemented in MXNet and how to create custom neural networks with these layers. * Also check out the guide to normalization layers to learn about neural network layers that normalize their inputs. * Finally take a look at the Custom Layer guide to learn how to implement your own custom activation layer.