oneDNN Quantization¶
Introduction¶
After successful model building and achieving desired accuracy on the test data, often the next step is to optimize inference to deploy the model to production. One of the key features of usable model is to have as small latency as possible to be able to provide services to large number of customers simultaneously. In addition to customer satisfaction, with well optimized model, hardware load is reduced which also reduces energy costs needed to perform inference.
Two main types of software optimizations can be characterized as: - memory-bound optimizations - main objective of these optimizations is to reduce the amount of memory operations (reads and writes) - it is done by e.g. chaining operations which can be performed one after another immediately, where input of every subsequent operation is the output of the previous one (example: ReLU activation after convolution), - compute-bound optimizations - these optimizations are mainly made on operations which require large number of CPU cycles to complete, like FullyConnected and Convolution. One of the methods to speedup compute-bound operations is to lower computation precision - this type of optimization is called quantization.
In version 2.0 of the Apache MXNet (incubating) GluonAPI2.0 replaced Symbolic API known from versions 1.x, thus there are some differences between API to perform graph fusion and quantization.
Operator Fusion¶
Models are often represented as a directed graph of operations (represented by nodes) and data flow (represented as edges). This way of visualizing helps a lot when searching for common patterns in whole model which can be optimized by fusion. Example: 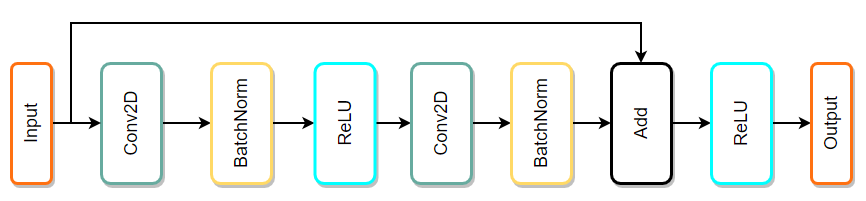
The simplest way to explain what fusion is and how it works is to present an example. Image above depicts a sequence of popular operations taken from ResNet architecture. This type of architecture is built with many similar blocks called residual blocks. Some possible fusion patterns are:
Conv2D + BatchNorm => Fusing BatchNorm with Convolution can be performed by modifing weights and bias of Convolution - this way BatchNorm is completely contained within Convolution which makes BatchNorm zero time operation. Only cost of fusing is time needed to prepare weights and bias in Convolution based on BatchNorm parameters.
Conv2D + ReLU => this type of fusion is very popular also with other layers (e.g. FullyConnected + Activation). It is very simple idea where before writing data to output, activation is performed on that data. Main benefit of this fusion is that, there is no need to read and write back data in other layer only to perform simple activation function.
Conv2D + Add => even simpler idea than the previous ones - instead of overwriting the output memory, results are added to it. In the simplest terms:
out_mem = conv_resultis replaced byout_mem += conv_result.
Above examples are presented as atomic ones, but often they can be combined together, thus two patterns that can be fused in above example are: - Conv2D + BatchNorm + ReLU - Conv2D + BatchNorm + Add + ReLU
After fusing all patterns, computational graph will be changed to the following one: 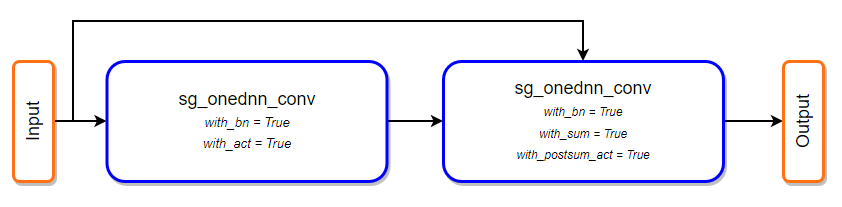
Operator fusion in MXNet¶
Since the version 1.6 of MXNet built with oneDNN support, operator fusion had been enabled by default for executing model with Module API, however in version 2.0 it has been decided to remove setting this feature by environment flag and replace it by aware user API call.
To fuse model in MXNet 2.0 there are two requirements: - the model must be defined as a subclass of HybridBlock or Symbol, - the model must have specific operator patterns which can be fused.
As an example we define sample block taken from ResNet architecture:
import mxnet as mx
from mxnet.gluon import nn
class SampleBlock(nn.HybridBlock):
def __init__(self):
super(SampleBlock, self).__init__()
self.conv1 = nn.Conv2D(channels=64, kernel_size=3, strides=1, padding=1,
use_bias=False, in_channels=64)
self.bn1 = nn.BatchNorm()
self.conv2 = nn.Conv2D(channels=64, kernel_size=3, strides=1, padding=1,
use_bias=False, in_channels=64)
self.bn2 = nn.BatchNorm()
def forward(self, x):
out = mx.npx.activation(self.bn1(self.conv1(x)), 'relu')
out = self.bn2(self.conv2(out))
out = mx.npx.activation(out + x, 'relu')
return out
net = SampleBlock()
net.initialize()
data = mx.np.zeros(shape=(1,64,224,224))
# run fusion
net.optimize_for(data, backend='ONEDNN')
# We can check fusion by plotting current symbol of our optimized network
sym, _ = net.export(None)
graph = mx.viz.plot_network(sym, save_format='png')
graph.view()
Both HybridBlock and Symbol classes provide API to easily run fusion of operators. Single line of code is enabling fusion passes on model:
net.optimize_for(data, backend='ONEDNN')
optimize_for function is available also as Symbol class method. Example call to this API is shown below. Notice that Symbol’s optimize_for method is not done in-place, so assigning it to a new variable is required:
optimized_symbol = sym.optimize_for(backend='ONEDNN')
For the above model definition in a naive benchmark with artificial data, we can gain up to 10.8x speedup without any accuracy loss on our testing machine with Intel(R) Xeon(R) Platinum 8375C CPU.
Quantization¶
As mentioned in the introduction, precision reduction is another very popular method of improving performance of workloads and, what is important, in most cases is combined together with operator fusion which improves performance even more. In training precision reduction utilizes 16 bit data types like bfloat or float16, but for inference great results can be achieved using int8.
Model quantization helps on both memory-bound and compute-bound operations. In quantized model IO operations are reduced as int8 data type is 4x smaller than float32, and also computational throughput is increased as more data can be SIMD’ed. On modern Intel architectures using int8 data type can bring even more speedup by utilizing special VNNI instruction set.
Firstly quantization performs operator fusion on floating-point model as mentioned in paragraph earlier. Next, all operators which support int8 data type are marked as quantized and if needed additional operators are injected into graph surrounding quantizable operator - the goal of this additional operators is to quantize, dequantize or requantize data to keep data type between operators compatible.

After injection step it is important to perform calibration of the model, however this step is optional. Quantizing without calibration is not recommended in terms of performance. It will result in calculating data minimum and maximum in quantize and requantize nodes during each inference pass. Calibrating a model greatly improves performance as minimum and maximum values are collected offline and are saved inside node - this way there is no need to search for these values during inference pass.

Currently, there are three supported calibration methods: - naive — min/max values from the calibration run, - entropy — uses KL divergence to determine the best symmetrical quantization thresholds for a given histogram of values, - custom — uses user-defined CalibrationCollector to control the calibration process.
Last stage of quantization flow is to perform additional operator fusion. Second fusion is about merging requantize and dequantize operators into preceding node - oneDNN kernels can perform needed scaling before writing result to output which results in model execution speed-up. Notice that last Convolution does not need minimum and maximum values as it is not requantizing int32 to int8, but dequantizing directly to float32 and scale is calculated basing on minimum and maximum of input and weights.

In MXNet 2.0, the quantization procedure has been adjusted to work well with Gluon models since it is the main API now. The goal was to allow the user to quantize fp32 HybridBlock model in just a few lines of code.
Quantization in MXNet¶
As an example of a quantization procedure, pretrained resnet50_v1 from model_zoo.vision package can be used. To get it simply run the following code:
import mxnet as mx
from mxnet.gluon.model_zoo.vision import resnet50_v1
net = resnet50_v1(pretrained=True)
Now, to get a ready-to-deploy quantized model two steps are required:
Prepare data loader with calibration data - this data will be used as input to the network. All necessary layers will be observed with layer collector to calculate minimum and maximum value of that layer. This flow is internal mechanism and all what user needs to do is to provide data loader.
Call
quantize_netfunction fromcontrib.quantizepackage - both operator fusion calls will be called inside this API.
calib_data_loader = mx.gluon.data.DataLoader(dummy_data, batch_size=batch_size)
qnet = quantize_net(net, calib_mode='naive', calib_data=calib_data_loader)
Following function, which calculates total inference time on the model with an artificial data, can be used to compare the performance:
def benchmark_net(net, batch_size=32, batches=100, warmup_batches=5):
import time
data = mx.np.random.uniform(-1.0, 1.0, (batch_size, 3, 224, 224))
for i in range(batches + warmup_batches):
if i == warmup_batches:
tic = time.time()
out = net(data)
out.wait_to_read()
total_time = time.time() - tic
return total_time
Comparing fused float32 network to quantized network on Intel(R) Xeon(R) Platinum 8375C CPU shows 4.2x speedup - measurment was done on 32 cores and this machine utilizes VNNI instruction set.
The other aspect of lowering the precision of a model is a difference in its accuracy. We will check that on previously tested resnet50_v1 with ImageNet dataset. To run this example you will need ImageNet dataset prepared with this tutorial and stored in path_to_imagenet. Let’s compare top1 and top5 accuracy of standard fp32 model with quantized int8 model calibrated using naive and entropy calibration mode. We will use only 10 batches of the validation dataset to calibrate quantized model.
import mxnet as mx
from mxnet.gluon.model_zoo.vision import resnet50_v1
from mxnet.gluon.data.vision import transforms
from mxnet.contrib.quantization import quantize_net
def test_accuracy(net, data_loader, description):
acc_top1 = mx.gluon.metric.Accuracy()
acc_top5 = mx.gluon.metric.TopKAccuracy(5)
count = 0
tic = time.time()
for x, label in data_loader:
count += 1
output = net(x)
acc_top1.update(label, output)
acc_top5.update(label, output)
time_spend = time.time() - tic
_, top1 = acc_top1.get()
_, top5 = acc_top5.get()
print('{:12} Top1 Accuracy: {:.4f} Top5 Accuracy: {:.4f} from {:4} batches in {:8.2f}s'
.format(description, top1, top5, count, time_spend))
rgb_mean = (0.485, 0.456, 0.406)
rgb_std = (0.229, 0.224, 0.225)
batch_size = 64
dataset = mx.gluon.data.vision.ImageRecordDataset('path_to_imagenet/val.rec')
transformer = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=rgb_mean, std=rgb_std)])
val_data = mx.gluon.data.DataLoader(dataset.transform_first(transformer), batch_size, shuffle=True)
net = resnet50_v1(pretrained=True)
net.hybridize(static_alloc=True, static_shape=True)
test_accuracy(net, val_data, "FP32")
dummy_data = mx.np.random.uniform(-1.0, 1.0, (batch_size, 3, 224, 224))
net.optimize_for(dummy_data, backend='ONEDNN', static_alloc=True, static_shape=True)
test_accuracy(net, val_data, "FP32 fused")
qnet = quantize_net(net, calib_mode='naive', calib_data=val_data, num_calib_batches=10)
qnet.hybridize(static_alloc=True, static_shape=True)
test_accuracy(qnet, val_data, 'INT8 Naive')
qnet = quantize_net(net, calib_mode='entropy', calib_data=val_data, num_calib_batches=10)
qnet.hybridize(static_alloc=True, static_shape=True)
test_accuracy(qnet, val_data, 'INT8 Entropy')
Output:¶
FP32 Top1 Accuracy: 0.7636 Top5 Accuracy: 0.9309 from 782 batches in 1560.97sFP32 fused Top1 Accuracy: 0.7636 Top5 Accuracy: 0.9309 from 782 batches in 281.03sINT8 Naive Top1 Accuracy: 0.7631 Top5 Accuracy: 0.9309 from 782 batches in 184.87sINT8 Entropy Top1 Accuracy: 0.7617 Top5 Accuracy: 0.9298 from 782 batches in 185.23s
With quantized model there is a tiny accuracy drop, however this is the cost of great performance optimization and memory footprint reduction. The difference between calibration methods is dependent on the model itself, used activation layers and the size of calibration data.
Custom layer collectors and calibrating the model¶
In MXNet 2.0 new interface for creating custom calibration collector has been added. Main goal of this interface is to give the user as much flexibility as possible in almost every step of quantization. Creating own layer collector is pretty easy, however computing effective min/max values can be not a trivial task.
Layer collectors are responsible for collecting statistics of each node in the graph — it means that the input/output data of every operator executed can be observed. Collector utilizes the register_op_hook method of HybridBlock class.
Custom layer collector has to inherit from the CalibrationCollector class, which is provided in contrib.quantization package. This inheritance allows API to be consistent. Below is an example implementation of CalibrationCollector:
class ExampleNaiveCollector(CalibrationCollector):
"""Saves layer output min and max values in a dict with layer names as keys.
The collected min and max values will be directly used as thresholds for quantization.
"""
def __init__(self, logger=None):
# important! initialize base class attributes
super(ExampleNaiveCollector, self).__init__()
self.logger = logger
def collect(self, name, op_name, arr):
"""Callback function for collecting min and max values from an NDArray."""
if name not in self.include_layers: # include_layers is populated by quantization API
return
arr = arr.copyto(cpu()).asnumpy()
min_range = np.min(arr)
max_range = np.max(arr)
if name in self.min_max_dict: # min_max_dict is by default empty dict
cur_min_max = self.min_max_dict[name]
self.min_max_dict[name] = (min(cur_min_max[0], min_range),
max(cur_min_max[1], max_range))
else:
self.min_max_dict[name] = (min_range, max_range)
if self.logger:
self.logger.debug("Collecting layer %s min_range=%f, max_range=%f"
% (name, min_range, max_range))
def post_collect(self):
# we're using min_max_dict and don't process any collected statistics so we don't
# need to override this function, however we are doing this for the sake of this article
return self.min_max_dict
Quantization API ‘injects’ names of nodes which require calibration into the include_layers attribute of custom collector — list of included layers allows to avoid unnecessary collecting on nodes which are not relevant in terms of quantization. Using this attribute is fully optional and user can implement his own logic.
After collecting all statistic data post_collect function is called. In post_collect additional processing logic can be implemented, but it must return dictionary of nodes names as key and tuple of minimum and maximum values which should be used to calculate data scaling factors.
Example of usage with quantization API:¶
from mxnet.contrib.quantization import *
import logging
logging.getLogger().setLevel(logging.DEBUG)
#…
calib_data_loader = mx.gluon.data.DataLoader(…)
my_collector = ExampleNaiveCollector(logger=logging.getLogger())
qnet = quantize_net(net, calib_mode='custom', calib_data=calib_data_loader, LayerOutputCollector=my_collector)
Performance and accuracy results¶
Performance¶
Performance results of CV models. Chart presents three different runs: base float32 model without optimizations, fused float32 model with optimizations and quantized model. 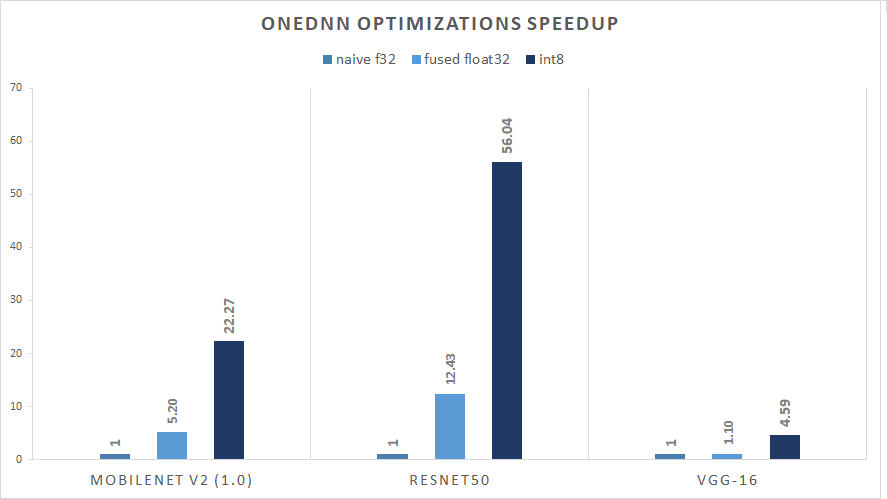 Figure 1. Relative Inference Performance (img/sec) for Batch Size 128
Figure 1. Relative Inference Performance (img/sec) for Batch Size 128
Accuracy¶
Accuracy results of CV models. Chart presents three different runs: base float32 model without optimizations, fused float32 model with optimizations and fused quantized model. 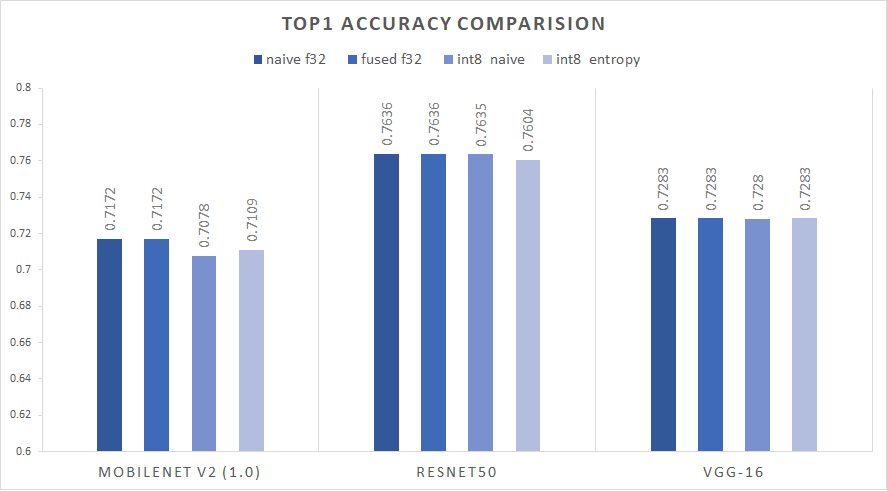 Figure 2. ImageNet(ILSVRC2012) TOP1 validation accuracy
Figure 2. ImageNet(ILSVRC2012) TOP1 validation accuracy
Notes¶
OMP_NUM_THREADS=32 OMP_PROC_BIND=TRUE OMP_PLACES={0}:32:1 (by benchmark/python/dnnl/run.sh)