Machine Translation with Transformer¶
In this notebook, we will show how to train Transformer introduced in [1] and evaluate the pretrained model using GluonNLP. The model is both more accurate and lighter to train than previous seq2seq models. We will together go through:
Use the state-of-the-art pretrained Transformer model: we will evaluate the pretrained SOTA Transformer model and translate a few sentences ourselves with the
BeamSearchTranslatorusing the SOTA model;Train the Transformer yourself: including loading and processing dataset, define the Transformer model, write train script and evaluate the trained model. Note that in order to obtain the state-of-the-art results on WMT 2014 English-German dataset, it will take around 1 day to have the model. In order to let you run through the Transformer quickly, we suggest you to start with the
TOYdataset sampled from the WMT dataset (by default in this notebook).
Preparation¶
Load MXNet and GluonNLP¶
import warnings
warnings.filterwarnings('ignore')
import random
import numpy as np
import mxnet as mx
from mxnet import gluon
import gluonnlp as nlp
Set Environment¶
np.random.seed(100)
random.seed(100)
mx.random.seed(10000)
ctx = mx.gpu(0)
Use the SOTA Pretrained Transformer model¶
In this subsection, we first load the SOTA Transformer model in GluonNLP model zoo; and secondly we load the full WMT 2014 English-German test dataset; and finally evaluate the model.
Get the SOTA Transformer¶
Next, we load the pretrained SOTA Transformer using the model API in GluonNLP. In this way, we can easily get access to the SOTA machine translation model and use it in your own application.
import nmt
wmt_model_name = 'transformer_en_de_512'
wmt_transformer_model, wmt_src_vocab, wmt_tgt_vocab = \
nmt.transformer.get_model(wmt_model_name,
dataset_name='WMT2014',
pretrained=True,
ctx=ctx)
print(wmt_src_vocab)
print(wmt_tgt_vocab)
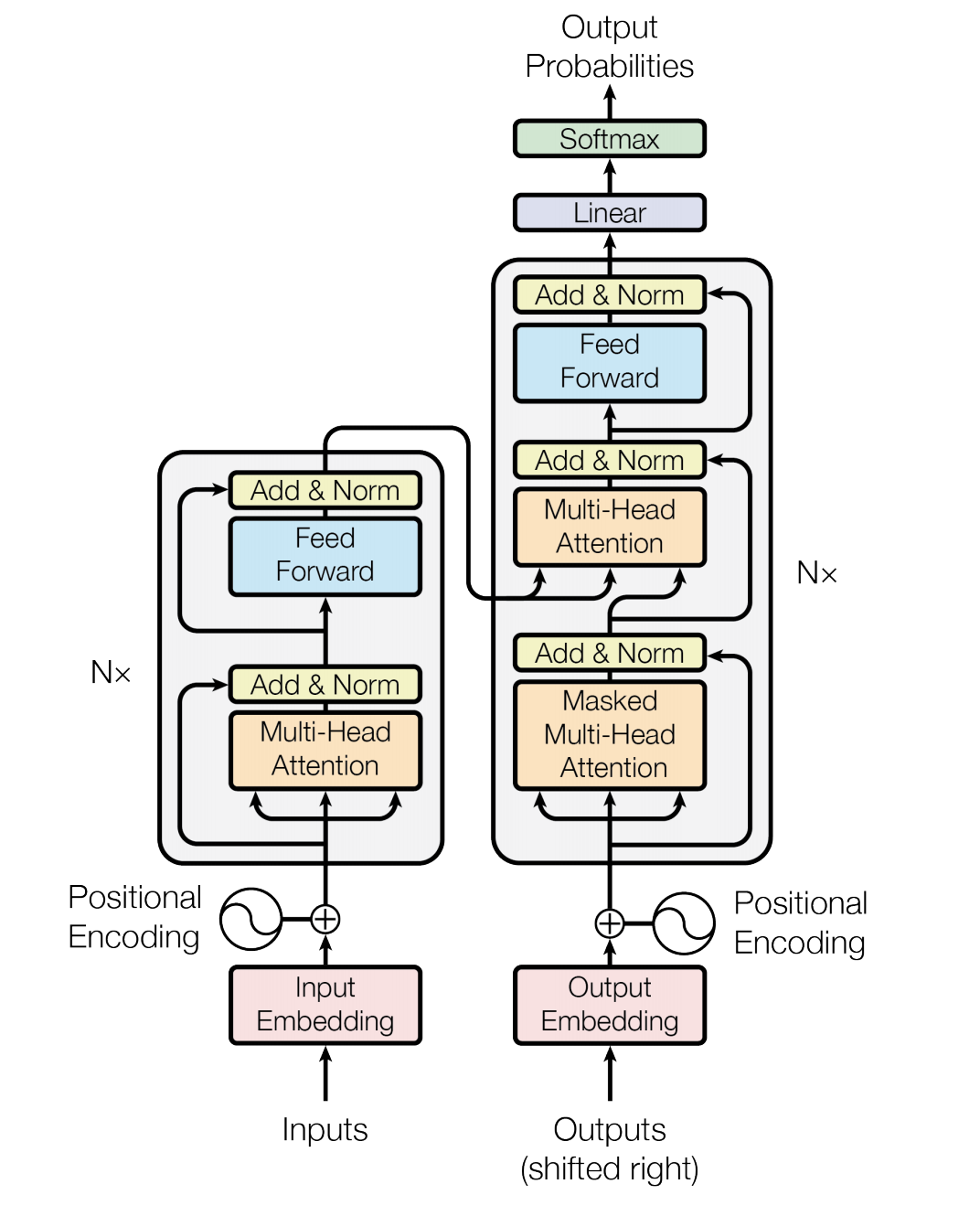
The Transformer model architecture is shown as below:
print(wmt_transformer_model)
Load and Preprocess WMT 2014 Dataset¶
We then load the WMT 2014 English-German test dataset for evaluation purpose.
The following shows how to process the dataset and cache the processed dataset for the future use. The processing steps include:
clip the source and target sequences
split the string input to a list of tokens
map the string token into its index in the vocabulary
append EOS token to source sentence and add BOS and EOS tokens to target sentence.
Let’s first look at the WMT 2014 corpus.
import hyperparameters as hparams
wmt_data_test = nlp.data.WMT2014BPE('newstest2014',
src_lang=hparams.src_lang,
tgt_lang=hparams.tgt_lang,
full=False)
print('Source language %s, Target language %s' % (hparams.src_lang, hparams.tgt_lang))
wmt_data_test[0]
wmt_test_text = nlp.data.WMT2014('newstest2014',
src_lang=hparams.src_lang,
tgt_lang=hparams.tgt_lang,
full=False)
wmt_test_text[0]
We then generate the target gold translations.
wmt_test_tgt_sentences = list(wmt_test_text.transform(lambda src, tgt: tgt))
wmt_test_tgt_sentences[0]
import dataprocessor
print(dataprocessor.TrainValDataTransform.__doc__)
wmt_transform_fn = dataprocessor.TrainValDataTransform(wmt_src_vocab, wmt_tgt_vocab, -1, -1)
wmt_dataset_processed = wmt_data_test.transform(wmt_transform_fn, lazy=False)
print(*wmt_dataset_processed[0], sep='\n')
Create Sampler and DataLoader for WMT 2014 Dataset¶
wmt_data_test_with_len = gluon.data.SimpleDataset([(ele[0], ele[1], len(
ele[0]), len(ele[1]), i) for i, ele in enumerate(wmt_dataset_processed)])
Now, we have obtained data_train, data_val, and data_test. The next step is to construct sampler and DataLoader. The first step is to construct batchify function, which pads and stacks sequences to form mini-batch.
wmt_test_batchify_fn = nlp.data.batchify.Tuple(
nlp.data.batchify.Pad(),
nlp.data.batchify.Pad(),
nlp.data.batchify.Stack(dtype='float32'),
nlp.data.batchify.Stack(dtype='float32'),
nlp.data.batchify.Stack())
We can then construct bucketing samplers, which generate batches by grouping sequences with similar lengths.
wmt_bucket_scheme = nlp.data.ExpWidthBucket(bucket_len_step=1.2)
wmt_test_batch_sampler = nlp.data.FixedBucketSampler(
lengths=wmt_dataset_processed.transform(lambda src, tgt: len(tgt)),
use_average_length=True,
bucket_scheme=wmt_bucket_scheme,
batch_size=256)
print(wmt_test_batch_sampler.stats())
Given the samplers, we can create DataLoader, which is iterable.
wmt_test_data_loader = gluon.data.DataLoader(
wmt_data_test_with_len,
batch_sampler=wmt_test_batch_sampler,
batchify_fn=wmt_test_batchify_fn,
num_workers=8)
len(wmt_test_data_loader)
Evaluate Transformer¶
Next, we generate the SOTA results on the WMT test dataset. As we can see from the result, we are able to achieve the SOTA number 27.35 as the BLEU score.
We first define the BeamSearchTranslator to generate the actual
translations.
wmt_translator = nmt.translation.BeamSearchTranslator(
model=wmt_transformer_model,
beam_size=hparams.beam_size,
scorer=nlp.model.BeamSearchScorer(alpha=hparams.lp_alpha, K=hparams.lp_k),
max_length=200)
Then we caculate the loss as well as the bleu score on the WMT
2014 English-German test dataset. Note that the following evalution
process will take ~13 mins to complete.
import time
import utils
eval_start_time = time.time()
wmt_test_loss_function = nmt.loss.SoftmaxCEMaskedLoss()
wmt_test_loss_function.hybridize()
wmt_detokenizer = nlp.data.SacreMosesDetokenizer()
wmt_test_loss, wmt_test_translation_out = utils.evaluate(wmt_transformer_model,
wmt_test_data_loader,
wmt_test_loss_function,
wmt_translator,
wmt_tgt_vocab,
wmt_detokenizer,
ctx)
wmt_test_bleu_score, _, _, _, _ = nmt.bleu.compute_bleu([wmt_test_tgt_sentences],
wmt_test_translation_out,
tokenized=False,
tokenizer=hparams.bleu,
split_compound_word=False,
bpe=False)
print('WMT14 EN-DE SOTA model test loss: %.2f; test bleu score: %.2f; time cost %.2fs'
%(wmt_test_loss, wmt_test_bleu_score * 100, (time.time() - eval_start_time)))
print('Sample translations:')
num_pairs = 3
for i in range(num_pairs):
print('EN:')
print(wmt_test_text[i][0])
print('DE-Candidate:')
print(wmt_test_translation_out[i])
print('DE-Reference:')
print(wmt_test_tgt_sentences[i])
print('========')
Translation Inference¶
We herein show the actual translation example (EN-DE) when given a source language using the SOTA Transformer model.
import utils
print('Translate the following English sentence into German:')
sample_src_seq = 'We love each other'
print('[\'' + sample_src_seq + '\']')
sample_tgt_seq = utils.translate(wmt_translator,
sample_src_seq,
wmt_src_vocab,
wmt_tgt_vocab,
wmt_detokenizer,
ctx)
print('The German translation is:')
print(sample_tgt_seq)
Train Your Own Transformer¶
In this subsection, we will go though the whole process about loading translation dataset in a more unified way, and create data sampler and loader, as well as define the Transformer model, finally writing training script to train the model yourself.
Load and Preprocess TOY Dataset¶
Note that we use demo mode (TOY dataset) by default, since loading
the whole WMT 2014 English-German dataset WMT2014BPE for the later
training will be slow (~1 day). But if you really want to train to have
the SOTA result, please set demo = False. In order to make the data
processing blocks execute in a more efficient way, we package them in
the load_translation_data (transform etc.) function used as
below. The function also returns the gold target sentences as well as
the vocabularies.
demo = True
if demo:
dataset = 'TOY'
else:
dataset = 'WMT2014BPE'
data_train, data_val, data_test, val_tgt_sentences, test_tgt_sentences, src_vocab, tgt_vocab = \
dataprocessor.load_translation_data(
dataset=dataset,
src_lang=hparams.src_lang,
tgt_lang=hparams.tgt_lang)
data_train_lengths = dataprocessor.get_data_lengths(data_train)
data_val_lengths = dataprocessor.get_data_lengths(data_val)
data_test_lengths = dataprocessor.get_data_lengths(data_test)
data_train = data_train.transform(lambda src, tgt: (src, tgt, len(src), len(tgt)), lazy=False)
data_val = gluon.data.SimpleDataset([(ele[0], ele[1], len(ele[0]), len(ele[1]), i)
for i, ele in enumerate(data_val)])
data_test = gluon.data.SimpleDataset([(ele[0], ele[1], len(ele[0]), len(ele[1]), i)
for i, ele in enumerate(data_test)])
Create Sampler and DataLoader for TOY Dataset¶
Now, we have obtained data_train, data_val, and data_test.
The next step is to construct sampler and DataLoader. The first step is
to construct batchify function, which pads and stacks sequences to form
mini-batch.
train_batchify_fn = nlp.data.batchify.Tuple(
nlp.data.batchify.Pad(),
nlp.data.batchify.Pad(),
nlp.data.batchify.Stack(dtype='float32'),
nlp.data.batchify.Stack(dtype='float32'))
test_batchify_fn = nlp.data.batchify.Tuple(
nlp.data.batchify.Pad(),
nlp.data.batchify.Pad(),
nlp.data.batchify.Stack(dtype='float32'),
nlp.data.batchify.Stack(dtype='float32'),
nlp.data.batchify.Stack())
target_val_lengths = list(map(lambda x: x[-1], data_val_lengths))
target_test_lengths = list(map(lambda x: x[-1], data_test_lengths))
We can then construct bucketing samplers, which generate batches by grouping sequences with similar lengths.
bucket_scheme = nlp.data.ExpWidthBucket(bucket_len_step=1.2)
train_batch_sampler = nlp.data.FixedBucketSampler(lengths=data_train_lengths,
batch_size=hparams.batch_size,
num_buckets=hparams.num_buckets,
ratio=0.0,
shuffle=True,
use_average_length=True,
num_shards=1,
bucket_scheme=bucket_scheme)
print('Train Batch Sampler:')
print(train_batch_sampler.stats())
val_batch_sampler = nlp.data.FixedBucketSampler(lengths=target_val_lengths,
batch_size=hparams.test_batch_size,
num_buckets=hparams.num_buckets,
ratio=0.0,
shuffle=False,
use_average_length=True,
bucket_scheme=bucket_scheme)
print('Validation Batch Sampler:')
print(val_batch_sampler.stats())
test_batch_sampler = nlp.data.FixedBucketSampler(lengths=target_test_lengths,
batch_size=hparams.test_batch_size,
num_buckets=hparams.num_buckets,
ratio=0.0,
shuffle=False,
use_average_length=True,
bucket_scheme=bucket_scheme)
print('Test Batch Sampler:')
print(test_batch_sampler.stats())
Given the samplers, we can create DataLoader, which is iterable. Note
that the data loader of validation and test dataset share the same
batchifying function test_batchify_fn.
train_data_loader = nlp.data.ShardedDataLoader(data_train,
batch_sampler=train_batch_sampler,
batchify_fn=train_batchify_fn,
num_workers=8)
print('Length of train_data_loader: %d' % len(train_data_loader))
val_data_loader = gluon.data.DataLoader(data_val,
batch_sampler=val_batch_sampler,
batchify_fn=test_batchify_fn,
num_workers=8)
print('Length of val_data_loader: %d' % len(val_data_loader))
test_data_loader = gluon.data.DataLoader(data_test,
batch_sampler=test_batch_sampler,
batchify_fn=test_batchify_fn,
num_workers=8)
print('Length of test_data_loader: %d' % len(test_data_loader))
Define Transformer Model¶
After obtaining DataLoader, we then start to define the Transformer. The
encoder and decoder of the Transformer can be easily obtained by calling
get_transformer_encoder_decoder function. Then, we use the encoder
and decoder in NMTModel to construct the Transformer model.
model.hybridize allows computation to be done using symbolic
backend. We also use label_smoothing.
encoder, decoder = nmt.transformer.get_transformer_encoder_decoder(units=hparams.num_units,
hidden_size=hparams.hidden_size,
dropout=hparams.dropout,
num_layers=hparams.num_layers,
num_heads=hparams.num_heads,
max_src_length=530,
max_tgt_length=549,
scaled=hparams.scaled)
model = nmt.translation.NMTModel(src_vocab=src_vocab, tgt_vocab=tgt_vocab, encoder=encoder, decoder=decoder,
share_embed=True, embed_size=hparams.num_units, tie_weights=True,
embed_initializer=None, prefix='transformer_')
model.initialize(init=mx.init.Xavier(magnitude=3.0), ctx=ctx)
model.hybridize()
print(model)
label_smoothing = nmt.loss.LabelSmoothing(epsilon=hparams.epsilon, units=len(tgt_vocab))
label_smoothing.hybridize()
loss_function = nmt.loss.SoftmaxCEMaskedLoss(sparse_label=False)
loss_function.hybridize()
test_loss_function = nmt.loss.SoftmaxCEMaskedLoss()
test_loss_function.hybridize()
detokenizer = nlp.data.SacreMosesDetokenizer()
Here, we build the translator using the beam search
translator = nmt.translation.BeamSearchTranslator(model=model,
beam_size=hparams.beam_size,
scorer=nlp.model.BeamSearchScorer(alpha=hparams.lp_alpha,
K=hparams.lp_k),
max_length=200)
print('Use beam_size=%d, alpha=%.2f, K=%d' % (hparams.beam_size, hparams.lp_alpha, hparams.lp_k))
Training Loop¶
Before conducting training, we need to create trainer for updating the parameter. In the following example, we create a trainer that uses ADAM optimzier.
trainer = gluon.Trainer(model.collect_params(), hparams.optimizer,
{'learning_rate': hparams.lr, 'beta2': 0.98, 'epsilon': 1e-9})
print('Use learning_rate=%.2f'
% (trainer.learning_rate))
We can then write the training loop. During the training, we perform the
evaluation on validation and testing dataset every epoch, and record the
parameters that give the hightest BLEU score on validation dataset.
Before performing forward and backward, we first use as_in_context
function to copy the mini-batch to GPU. The statement
with mx.autograd.record() will locate Gluon backend to compute the
gradients for the part inside the block. For ease of observing the
convergence of the update of the Loss in a quick fashion, we set the
epochs = 3. Notice that, in order to obtain the best BLEU score, we
will need more epochs and large warmup steps following the original
paper as you can find the SOTA results in the first subsection. Besides,
we use Averaging SGD [2] to update the parameters, since it is more
robust for the machine translation task.
best_valid_loss = float('Inf')
step_num = 0
#We use warmup steps as introduced in [1].
warmup_steps = hparams.warmup_steps
grad_interval = hparams.num_accumulated
model.setattr('grad_req', 'add')
#We use Averaging SGD [2] to update the parameters.
average_start = (len(train_data_loader) // grad_interval) * \
(hparams.epochs - hparams.average_start)
average_param_dict = {k: mx.nd.array([0]) for k, v in
model.collect_params().items()}
update_average_param_dict = True
model.zero_grad()
for epoch_id in range(hparams.epochs):
utils.train_one_epoch(epoch_id, model, train_data_loader, trainer,
label_smoothing, loss_function, grad_interval,
average_param_dict, update_average_param_dict,
step_num, ctx)
mx.nd.waitall()
# We define evaluation function as follows. The `evaluate` function use beam search translator
# to generate outputs for the validation and testing datasets.
valid_loss, _ = utils.evaluate(model, val_data_loader,
test_loss_function, translator,
tgt_vocab, detokenizer, ctx)
print('Epoch %d, valid Loss=%.4f, valid ppl=%.4f'
% (epoch_id, valid_loss, np.exp(valid_loss)))
test_loss, _ = utils.evaluate(model, test_data_loader,
test_loss_function, translator,
tgt_vocab, detokenizer, ctx)
print('Epoch %d, test Loss=%.4f, test ppl=%.4f'
% (epoch_id, test_loss, np.exp(test_loss)))
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
model.save_parameters('{}.{}'.format(hparams.save_dir, 'valid_best.params'))
model.save_parameters('{}.epoch{:d}.params'.format(hparams.save_dir, epoch_id))
mx.nd.save('{}.{}'.format(hparams.save_dir, 'average.params'), average_param_dict)
if hparams.average_start > 0:
for k, v in model.collect_params().items():
v.set_data(average_param_dict[k])
else:
model.load_parameters('{}.{}'.format(hparams.save_dir, 'valid_best.params'), ctx)
valid_loss, _ = utils.evaluate(model, val_data_loader,
test_loss_function, translator,
tgt_vocab, detokenizer, ctx)
print('Best model valid Loss=%.4f, valid ppl=%.4f'
% (valid_loss, np.exp(valid_loss)))
test_loss, _ = utils.evaluate(model, test_data_loader,
test_loss_function, translator,
tgt_vocab, detokenizer, ctx)
print('Best model test Loss=%.4f, test ppl=%.4f'
% (test_loss, np.exp(test_loss)))
Conclusion¶
Showcase with Transformer, we are able to support the deep neural networks for seq2seq task. We have already achieved SOTA results on the WMT 2014 English-German task.
Gluon NLP Toolkit provides high-level APIs that could drastically simplify the development process of modeling for NLP tasks sharing the encoder-decoder structure.
Low-level APIs in NLP Toolkit enables easy customization.
Documentation can be found at https://gluon-nlp.mxnet.io/index.html
Code is here https://github.com/dmlc/gluon-nlp
References¶
[1] Vaswani, Ashish, et al. “Attention is all you need.” Advances in Neural Information Processing Systems. 2017.
[2] Polyak, Boris T, and Anatoli B. Juditsky. “Acceleration of stochastic approximation by averaging.” SIAM Journal on Control and Optimization. 1992.